

HTTP란?
HyperText Transfer Protocol의 약자로 즉 문서 간에 링크를 통해서 서로 연결할 수 있는 HTML을 전송하는 프로토콜로 처음 시작
→ 1991년 웹 서버와 WWW 통신을 [HTTP v0.9]라는 이름으로 문서화하고 이 프로토콜을 표준화함
하지만 지금은 모든 것을 HTTP 프로토콜로 전송을 함. 거의 모든 형태의 데이터를 전송할 수 있고 클라이언트-서버만이 아닌 서버 간에 데이터를 주고받을 때도 HTTP 프로토콜을 사용함 [TCP 프로토콜로 서번 간 연결하여 데이터 전송은 드문 편]
- HTML, TEXT
- IMAGE, 음성, 영상, 파일
- JSON, XML (API)
- 거의 모든 형태의 데이터 전송 가능
- 서번 간 데이터를 주고 받을 때도 대부분 HTTP 사용
- 결국 REST API는 HTTP 프로토콜의 인프라를 그대로 사용하여 설계하는 아키텍처 방식이므로 HTTP 특징과 사용법에 대해서 잘 숙지하는 것이 매우 중요
HTTP 역사
- HTTP/0.9 1991년 : GET 메서드만 지원, HTTP 헤더 X
- HTTP/1.0 1996년 : 메서드, 헤더 추가
- HTTP/1.1 1997년 : 가장 많이 사용, 가장 중요한 버전
- HTTP/2 2015년 : 성능 개선 → 현재 가장 많이 사용됨
- HTTP/3 진행 중 : TCP 대신에 UDP 사용 성능 개선
기본 뼈대는 HTTP 1.1 버전이고 추후 버전은 성능 개선에 포커싱이 되어 있기 때문에 1.1 버전에 대해서 잘 아는 것이 중요
기반 프로토콜
- TCP : HTTP/1.1 → TCP를 기반하므로 3 way handshake에 의해 기본적으로 빠른 프로토콜은 아님
- UDP : HTTP → TCP의 성능을 최적화해서 나온 것이 UDP 프로토콜
- 현재 HTTP/1.1 주로 사용 → 최근에는 성능 개선된 HTTP2가 많이 사용됨
- 밑의 이미지에서 h2는 HTTP2를 의미

HTTP 특징
1️⃣ 클라이언트 서버 구조
- Request Response 구조
- 클라이언트가 HTTP 메시지를 통해서 서버에 요청을 보냄 ↔ 서버는 클라이언트에서 메시지가 올 때까지 무한정 기다림
- 서버가 요청에 대한 처리를 하여 결과에 응답을 하면 응답 결과를 열어서 클라이언트가 동작
- 클라이언트와 서버의 개념을 분리한다는 것이 중요
- 비즈니스 로직과 데이터 관련 된 것을 서버에 집중 시킴
- 클라이언트는 UI와 사용성에 집중을 함
- 클라이언트와 서버가 각각 독립적으로 진화할 수 있는 환경에 기반이 됨

2️⃣ 무상태 프로토콜(stateless) 지향
- 서버가 클라이언트의 상태를 보존하지 않음
- 클라이언트 서버 아키텍처에서는 이러한 방식이 엄청난 확장성을 가지고 옴
- 장점 : 서버 확장성 높음(scale out)
- 단점 : 클라이언트의 추가 데이터 전송 필요
- 반대 개념은 Stateful(상태 지향)
- Stateless & Stateful 란 무엇일까요? (아래 더보기 클릭)
1) 예제 - 같은 점원인 경우 (Stateful) - 서버가 클라이언트의 상태를 보존
- 고객 : 이 휴대폰 얼마인가요?
- 점원 : 100만원입니다.
- 고객 : 2개 구매하겠습니다.
- 점원 : 200만원 입니다. 어떻게 결제하시겠어요?
- 고객 : 신용카드로 구매하겠습니다.
- 점원 : 200만원 결제 완료되었습니다.
위 내용을 풀어서 보면 아래와 같습니다
- 고객 : 이 휴대폰 얼마인가요?
- 점원 : 100만원입니다. (휴대폰 상태 유지)
- 고객 : 2개 구매하겠습니다.
- 점원 : 200만원 입니다. 어떻게 결제하시겠어요? (휴대폰, 2개 상태 유지)
- 고객 : 신용카드로 구매하겠습니다.
- 점원 : 200만원 결제 완료되었습니다.(휴대폰, 2개, 신용카드 상태 유지)
문맥이 사라지기 때문에 상태 유지에서는 중간에 점원이 바뀌면 장애가 난다.
2) 예제 - 점원이 중간에 바뀐 경우 (Stateless)
- 고객 : 이 휴대폰 얼마인가요?
- 점원A : 100만원입니다.
- 고객 : 2개 구매하겠습니다.
- 점원B : ? 무엇을 2개 구매하시나요?
- 고객 : 신용카드로 구매하겠습니다.
- 점원C : ? 무슨 제품을 몇개 신용카드로 구매하겠어요?
Stateless에서 클라이언트의 요청 방법
- 고객 : 이 휴대폰 얼마인가요?
- 점원A : 100만원입니다.
- 고객 : 휴대폰 2개 구매하겠습니다.
- 점원B : 휴대폰 2개는 200만원 입니다. 어떻게 결제 하시겠어요?
- 고객 : 휴대폰 2개를 신용카드로 구매하겠습니다.
- 점원C : 200만원 결제 완료 되었습니다.
1. 고객이 필요한 데이터를 그때그때 다 넘긴다.
2. 그렇기 때문에 중간에 점원이 바뀌어도 아무런 문제가 없다.
3) Stateful, Stateless 차이
- 상태 유지(Stateful) : 중간에 다른 점원으로 바뀌면 안된다.
- (중간에 다른 점원으로 바뀔 때 상태 정보를 다른 점원에게 미리 알려줘야 한다)
- 무상태(Stateless) : 중간에 다른 점원으로 바뀌어도 된다.
- 갑자기 고객이 증가해도 점원을 대거 투입할 수 있다.
- 갑자기 클라이언트 요청이 증가해도 서버를 대거 투입할 수 있다.
- 무상태는 응답 서버를 쉽게 바꿀 수 있다(상태 유지를 하지 않기 때문) → 무한한 서버 증설 가능
1️⃣ Stateful
- 항상 같은 서버가 유지되어야 한다.
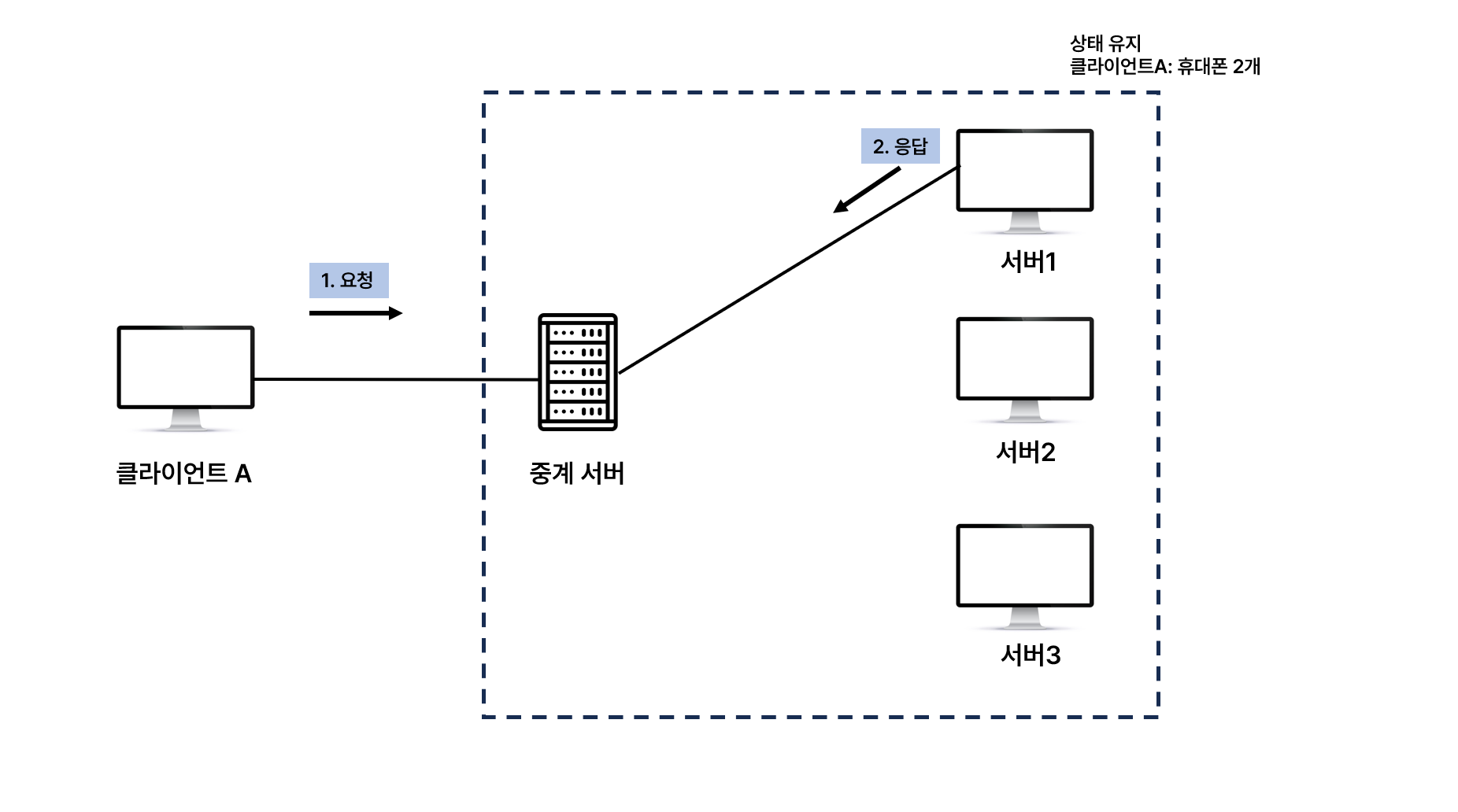
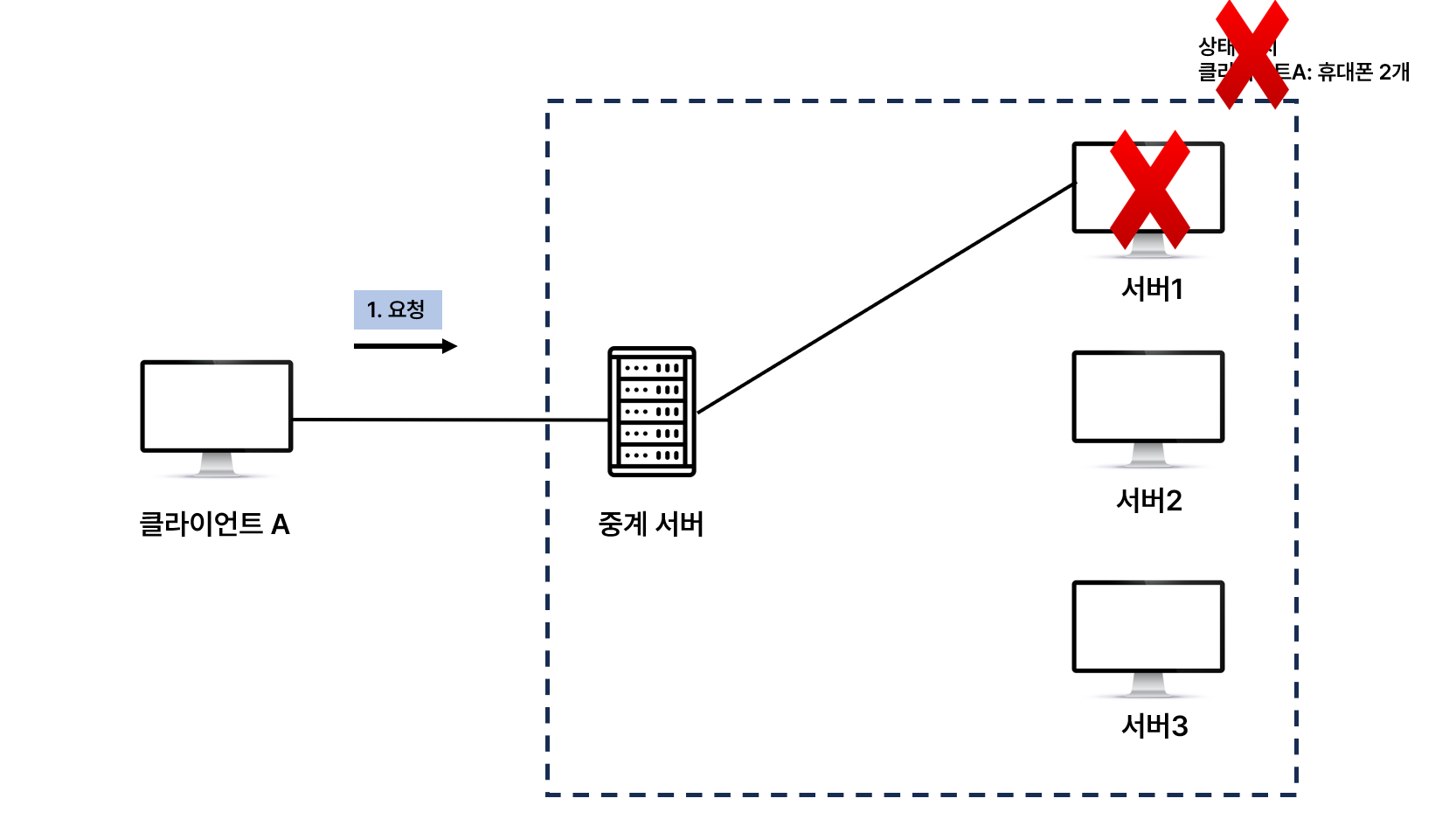
- 중간에 서버 장애가 나면?
- 처음부터 결제를 다시 진행해야 한다.
2️⃣ Stateless
- 요청에 모든 요청 사항 포함(물품, 수량, 결제 방법)
- 서버는 상태를 보관하지 않음

- 중간에 서버 장애가 나면?
- 갑자기 서버1 장애가 나도 클라이언트A는 중계 서버를 통해 정상 작동중인 서버 2로메시지 전달
- 서버에서는 클라이언트 메시지에 필요한 내용이 다 담겨 있으므로 응답 가능
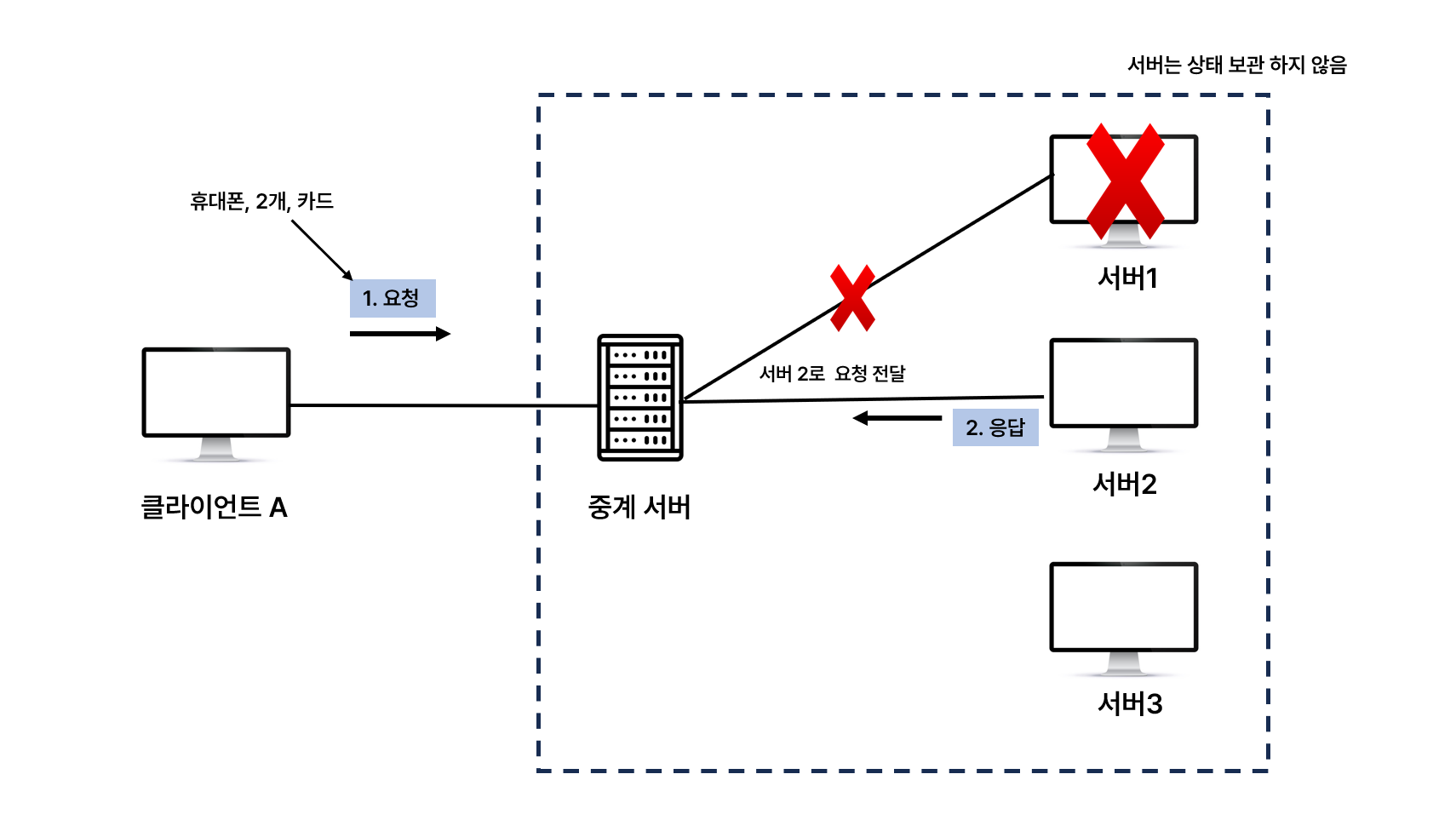
이처럼 Stateless는 아래와 같이 서버를 늘리는 스케일 아웃에 굉장히 유리함
예를 들어 큰 이벤트를 할 경우 장비를 수십, 수 백대로 설계하는 것이 가능해짐

🚩 Stateless 실무 한계
- 모든 것을 무상태로 설계 할 수 있는 경우도 있고 없는 경우도 존재
- 무상태
- 예) 로그인이 필요 없는 단순한 서비스 소개 화면
- 상태 유지
- 예 ) 로그인
- 로그인한 사용자의 경우 로그인 했다는 상태를 서버에 유지
- 일반적으로 브라우저 쿠키와 서버 세션 등을 사용해서 상태 유지
- 상태 유지는 어쩔 수 없는 경우 최소한만 사용하는 것을 지향함
- Stateless는 데이터를 너무 많이 보내야 한다는 단점도 존재
3️⃣ 비 연결성
- HTTP는 기본이 연결을 유지하지 않는 모델
- 일반적으로 초 단위 이하의 빠른 속도로 응답
- 실제 동시에 처리하는 요청의 개수는 수십 개 이하로 매우 작음
- ex) 웹 브라우저에서 계속 연속해서 검색 버튼을 누르지 않는다
- 서버 자원을 매우 효율적으로 사용 가능함
단점
- TCP/IP 연결을 새로 맺어야 함 - 3 way handshake 시간 추가
- 웹 브라우저로 사이트를 요청하면 HTML 뿐 아니라 자바스크립트, css, 이미지 등 수많은 자원이 함께 다운로드
- 지금은 HTTP 지속 연결(Persistent Connections)로 문제 해결
- 몇십 초 동안 연결을 짧게 유지
- 지금은 HTTP 지속 연결(Persistent Connections)로 문제 해결
- HTTP/2, HTTP/3에서 더 많은 최적화
정리
Stateless 하게 설계하는 것이 서버 개발자에게 있어 가장 중요 서버 개발자들이 가장 어려워하는 것이 동 시간대 대용량 트래픽이 발생하는 것을 가장 어려워함
예) 선착순 이벤트, 수강 신청, 명절 KTX 예약
예) 배달의 민족에서 18:00시 선착순 10000명 할인 쿠폰 이벤트 → 수 만 명 동시 요청
최대한 Stateless 하게 설계를 해야 위와 같이 대용량 트랙픽이 발생하는 예시 상황에서 서버를 확장하여 대응을 할 수 있는 부분이 많아짐
4️⃣ HTTP 메시지

- URI
- 접근해야 하는 리소스가 어디 있는지 알 수 있는 주소
- Uniform : 리소스 식별하는 통일된 방식
- Resource : 자원, URI로 식별할 수 있는 모든 것
- Identifier : 다른 항목과 구분하는데 필요한 정보
- 프로토콜(http)
- 호스트명(www.example.com)
- 포트 번호(80, 443)
- 패스(/search)
- 쿼리 파라미터(?keyWord=hello&lang=ko)
- URI와 URL 은 같은 의미로 통용됨
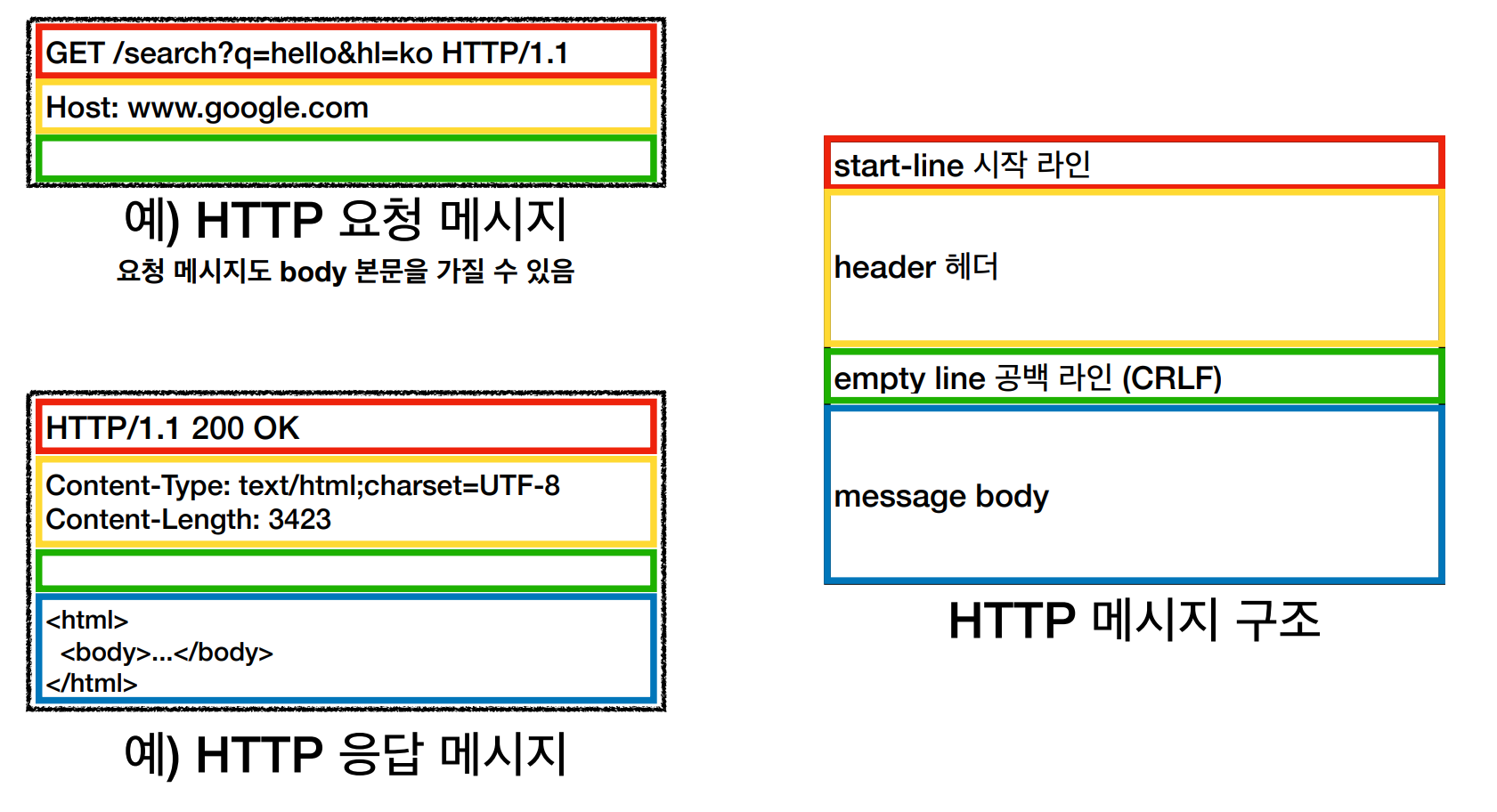
📌 요청 메시지 구조
✅ 시작 라인 - HTTP 메서드
- 시작은 request-line = 1. method SP(공백) 2. request-target(path)SP 3.HTTP-version CRLF(엔터)
- 종류 : GET, POST, PUT, PATCH, DELETT …
- 서버가 수행해야 할 동작 지정
- GET : 리소스 조회
- POST : 요청 내역 처리

✅ 시작 라인 - HTTP 버전
- HTTP Version

📌응답 메시지 구조
- 시작은 status-line = HTTP-version SP status-code SP reason-phrase CRLF

- HTTP 버전
- HTTP 상태 코드 : 요청 성공, 실패
- 200 : 성공
- 400 : 클라이언트 요청 오류
- 500 : 서버 오류
✅ HTTP 헤더
- header-field = field-name “:” OWS field-value OWS (OWS : 띄어쓰기 허용)

- 용도
- HTTP 전송에 필요한 모든 부가 정보
- ex) 메시지 바디의 내용, 메시지 바디의 크기, 인증, 요청 클라이언트의 웹 브라우저 정보, 캐시 관리 정보 등
- 표준 헤더 많음
- 필요시 임의의 헤더 추가 가능
✅ HTTP 메시지 바디
- 실제 전송할 데이터
- HTML 문서, 이미지, 영상, JSON 등 byte로 표현할 수 있는 모든 데이터 전송 가능

HTTP 메서드
가장 중요한 것은 리소스 식별
API URI 고민
- 리소스의 의미는 무엇?
- 회원을 등록하고 수정하고 조회하는 게 리소스가 아님
- 회원의 조회해! → 회원이 리소스
- 회원이라는 개념 자체가 리소스이다.
- 틀린 설계 (x)
- 회원 조회 /members/{id}/search
- 회원 등록 /member/{id}/regist
- 회원 수정 /member/{id}/modify
- 회원 삭제 /members/{id}delete
- 리소스를 어떻게 식별하는가?
- 회원을 등록하고 수정하고 조회하는 것을 모두 배제 → 즉 동사 배제
- 회원이라는 리소스만 식별하면 된다. → 회원 리소스를 URI에 매핑
- API 설계
- 회원 목록 조회 /members
- 회원 조회 /members/{id}
- 회원 등록 /members/{id}
- 회원 수정 /members/{id}
- 회원 삭제 /members/{id}
리소스를 통해서 자원을 식별하였는데 다 똑같은 구조.. 그럼 어떻게 구별할까?
리소스와 행위를 분리
- URI는 리소스만 식별
- 리소스와 해당 리소스를 대상으로 하는 행위를 분리
- 리소스 : 회원
- 행위 : 등록, 조회, 변경, 삭제 (CRUD)
- 리소스는 명사, 행위는 동사
- 행위(메서드)는 어떻게 구분?
📂 HTTP 메서드 종류
| GET | 리소스 조회 |
| POST | 요청 데이터 처리, 주로 등록에 사용 |
| PUT | 리소스 대체, 해당 리소스가 없으면 생성 |
| PATCH | 리소스 부분 변경 |
| DELETE | 리소스 삭제 |
📂 기타 메서드 종류
| HEAD | GET과 동일하지만 body 부분을 제외하고, 상태 줄과 헤더만 반환 |
| OPTIONS | 대상 리소스에 대한 통신 가능 옵션(메서드)을 설명 |
| CONNECT | 대상 자원으로 식별되는 서버에 대한 터널을 설정 |
| TRACE | 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행 |
- 맞는 설계(O)
- 행위를 통해 자원을 식별
- 회원 목록 조회 (GET) /members
- 회원 조회 (GET) /members/{id}
- 회원 등록 (POST) /members/{id}
- 회원 수정 (PUT) /members/{id}
- 회원 삭제 (DELETE) /members/{id}
- 행위를 통해 자원을 식별
📌 GET
- 리소스 조회용
- 주로 검색, 게시판 목록에서 정렬 필터(검색어)
- 서버에 전달하고 싶은 데이터는 query(쿼리 파라미터, 쿼리 스트링)를 통해서 전달
- 메시지 바디를 사용해서 데이터를 전달할 수 있지만, 지원하지 않는 곳이 많아서 권장하지 않음
GET /search?keyWord=hello&language=ko HTTP/1.1
Host: www.example.com
GET 요청 예시 (아래 더보기 클릭)
1) 메시지 전달
- 회원 중 100번의 데이터 요청
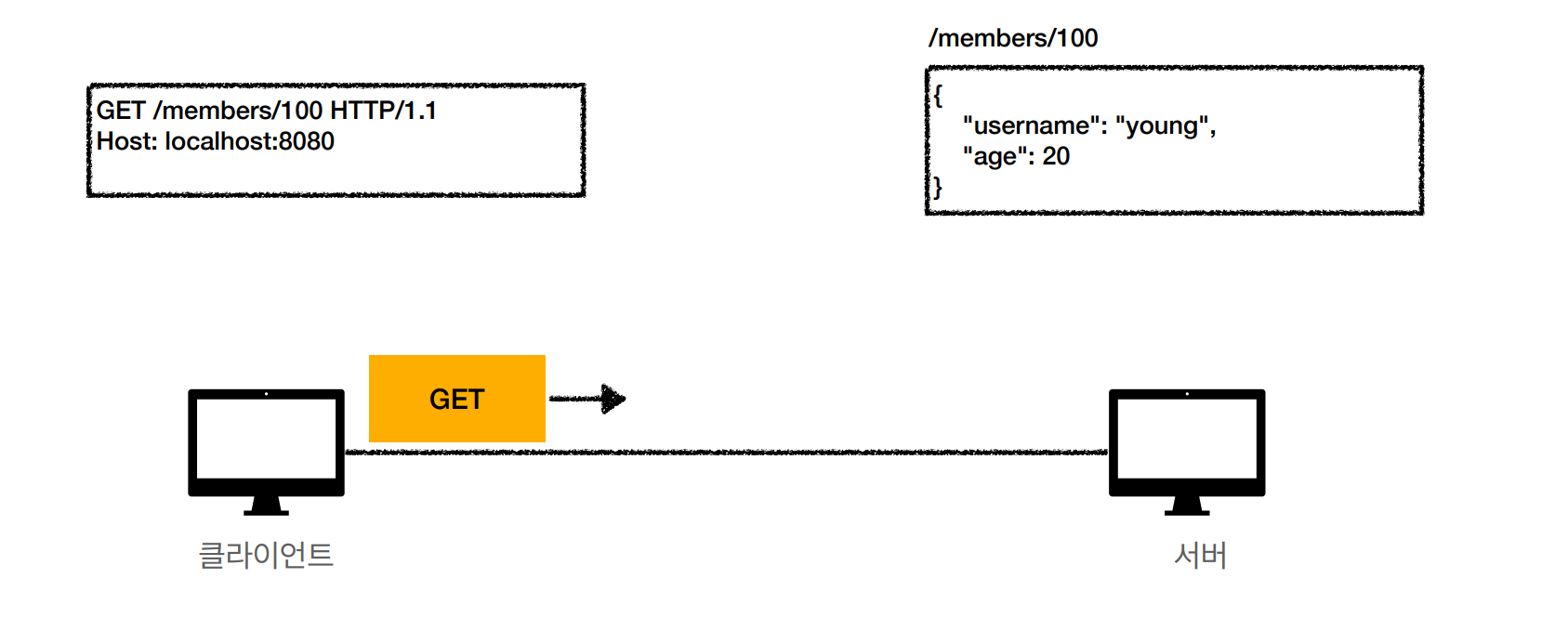
2) 서버 도착
- 서버는 요청 메시지를 받아 100 회원의 정보를 DB 에서 조회
- json 형식으로 데이터 생성

3) 데이터 응답
- HTTP 버전과 200 OK 명시
- 생성된 데이터 형식 Content-Type에 명시
- 클라이언트에게 전달 → 클라이언트에서 이 데이터를 가지고 화면을 그림

📌 POST
🟪 특징
- 요청 데이터 처리 역할
- 메시지 body 통해 서버로 요청 데이터 전달
- 서버는 요청 데이터를 처리
- 메시지 body 통해 들어온 데이터를 처리하는 모든 기능을 수행
- 주로 전달된 데이터로 신규 리소스 등록, 프로세스 처리에 사용
POST 요청 예시(아래 더보기 클릭)
1) 리소스 등록
- /members → 회원 등록 요청

2) 신규 리소스 생성
- 서버에서 POST /members 로 온 요청을 보고 회원 생성 요청인 것을 판단
- 신규 리소스 식별자(신규 회원 id) 생성 → 100번 생성
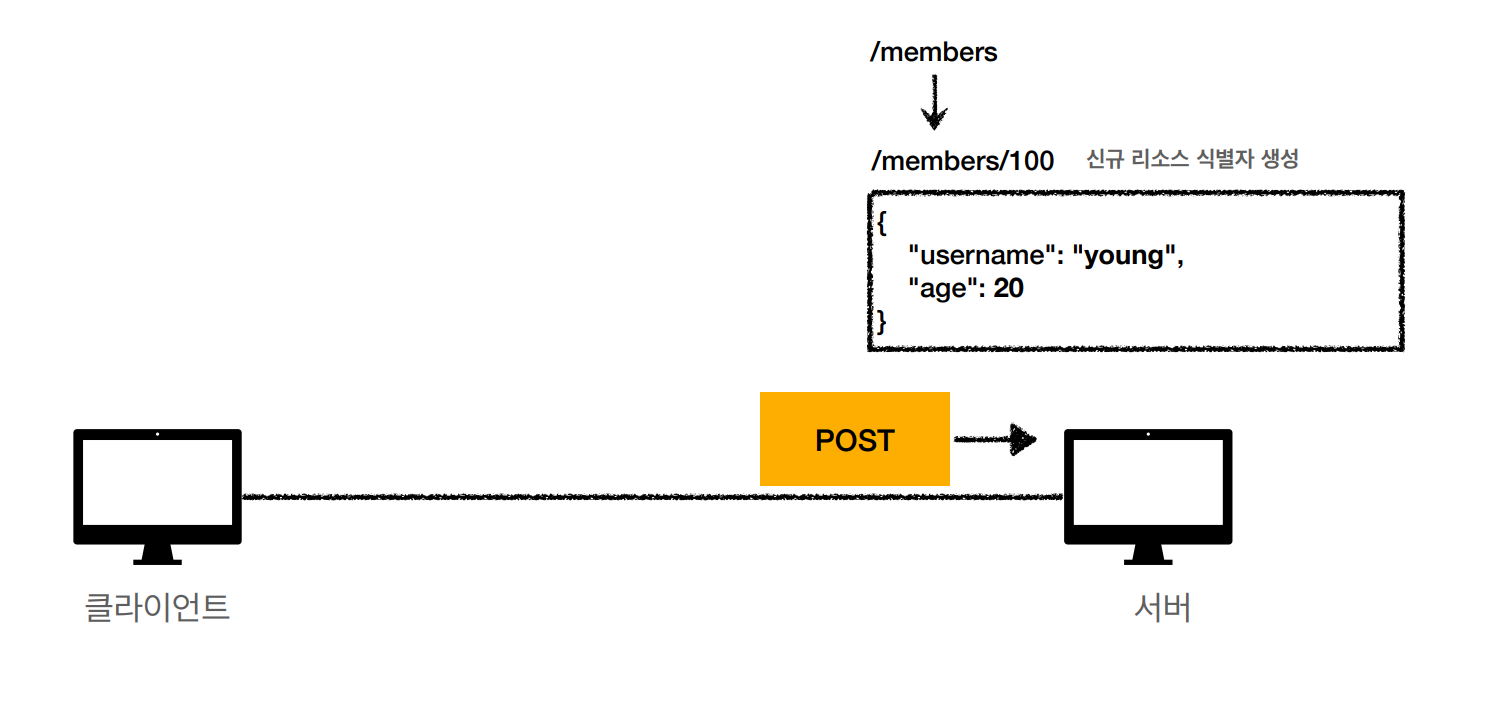
3) 응답 데이터
- 201 Created 로 응답
- Location → 자원의 신규 생성된 경로를 Location 헤더에 실어 보냄
- Body → 등록된 데이터를 실어서 어떤 데이터가 생성되었는지 클라이언트에게 알려줌
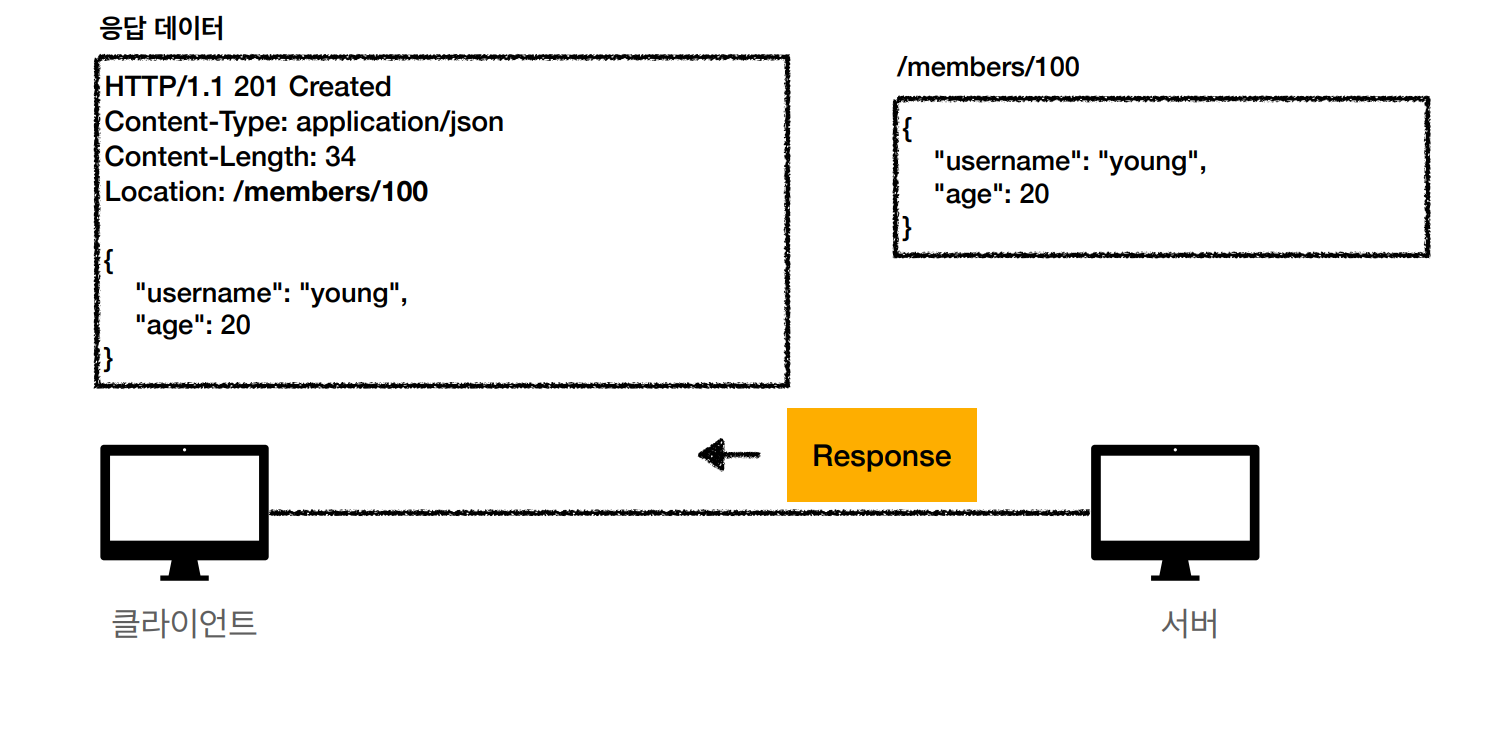
🟪 POST의 예시
- HTML 양식에 입력된 필드와 같은 데이터 블록을 데이터 처리 프로스스에 제공
- ex) HTML FROM에 입력한 정보로 회원 가입, 주문 등에서 사용
- 게시판, 뉴스 그룹, 메일링 리스트, 블로그 또는 유사한 기사 그룹에 메시지 게시
- ex) 게시판 글쓰기, 댓글 쓰기
- 서버가 아직 식별하지 않은 새 리소스 생성
- ex) 신규 주문 생성
- 기존 자원에 데이터 추가
- ex) 한 문서 끝에 내용 추가하기
🟪 POST 정리
- 새 리소스 생성(등록) 시 사용
- 요청 데이터 처리 시 사용
- 단순히 데이터를 생성하거나 변경하는 것을 넘어 프로세스를 처리해야 하는 경우
- 예) 로그인, 결제 완료, 배달 시작 → 배달 완료처럼 단순히 값 변경을 넘어 프로세스의 상태가 변경되는 경우
- POST의 결과로 새로운 리소스가 생성되지 않을 수 도 있음 → 큰 프로세스가 실행되는 것은 post
- 예) POST /orders/{orderId}/start-delivery (컨트롤 URI) → 실무에서는 리소스만 가지고 URI 다 설계가 불가 / 최대한 리소스로만 가지고 URI 설계하되 어쩔 수 없는 경우 컨트롤 URI로 설계
- 다른 메서드로 처리하기 애매한 경우 사용
- 예) JSON으로 조회 데이터를 넘겨야 하는데, GET 메서드를 사용하기 어려운 경우
- 하지만 조회의 경우 웬만하면 GET 사용 → 캐싱 (HTTP 메서드의 속성)
- POST도 캐싱은 가능하지만 캐싱하기 까다로움
📌 PUT
- 리소스 대체 역할
- 리소스가 있으면 완전히 대체
- 리소스가 없으면 생성
- 쉽게 말하면 기존 데이터를 완전히 덮어버림
- Body 에는 덮어쓸 데이터만 위치 시킴
- POST와 차이점
- 클라이언트가 리소스를 식별
- 즉 클라이언트가 리소스 위치를 알고 URI 직접 지정해야
PUT 요청 예시(아래 더보기 클릭)
1) 리소스 있는 경우 - 요청

1) 리소스 있는 경우 - 요청 처리
- 기존 데이터를 덮어버려 대체가

2) 리소스 없는 경우

3) 리소스가 완전히 대체되는 것을 주의 - 1
- username 필드를 지우고 요청

3) 리소스가 완전히 대체 되는 것을 주의 - 2
- username 필드가 삭제 되어 버림
- 기존 리소스 삭제하고 덮어 버려서 username 필드 자체가 없어짐

put은 결국 기존 리소스를 수정하는 것이 아닌 완전히 갈아 치우는 행위임을 주의❗
📌 PATCH
- 리소스 부분 변경
PATCH 요청 예시(아래 더보기 클릭)
- 요청
- username 제외 하고 요청

- 처리
- 명시된 age만 부분 수정
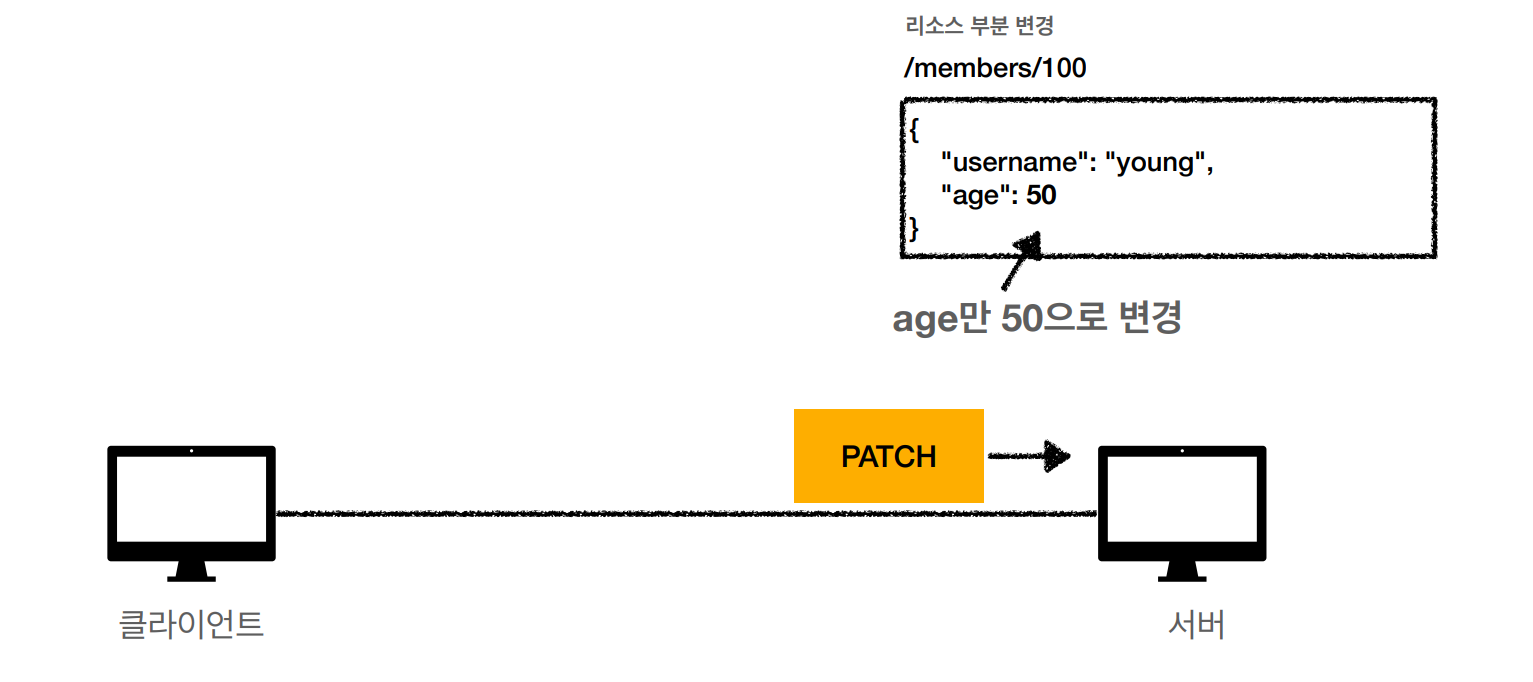
📌 DELETE
- 리소스 제거
DELETE /members?100 HTTP/1.1
Host: www.example.com
HTTP 메서드 속성

🟪 안전 (Safe)
- 호출해도 리소스를 변경하지 않는다.
- 여러 번 호출했을 때 변경이 일어나는 것은 safe 하지 않음(POST, PUT…)
- GET과 같이 단순 조회만 하는 메서드
- 계속 호출하면서 로그가 계속 쌓여 오류가 나면?
- 안전 속성은 리소스에 대한 것만 고려
🟪 멱등 (Idempotent)
- f(f(x)) = f(x)
- 한 번 호출 하든 두 번 호출하든 호출 횟수와 관계없이 결과가 똑같음
- 최종 결과물에 초점을 맞추어야 함
- 멱등 메서드
- GET : 한 번 조회하든, 두 번 조회하든 같은 결과가 조회
- PUT : 결과를 대체. 같은 요청을 여러 번 해도 최종 결과는 같음
- DELETE : 결과 삭제. 같은 요청을 여러 번 해도 삭제된 결과는 같음
- POST : 멱등하지 않음. 여러 번 호출하면 계속해서 리소스 생성 (결제, 배송 등)
- 자동 복구 메커니즘에 활용
- 예 ) 클라이언트에서 DELETE를 호출하였는데 서버에서 응답이 없음. DELETE 멱등 하기 때문에 다시 요청해도 괜찮음.
- 똑같은 요청을 두 번 해도 결과는 항상 같으므로 이러한 자동 복구 메커니즘에 활용 가능
- 재 요청 중간에 다른 곳에서 리소스를 변경하면?
- 사용자 1 : GET → username : A, age : 20
- 사용자 2 : PUT → username : A, age : 10
- 사용자 1 : GET → username : A , age : 10 → 사용자 2의 변경에 의해 age가 변경됨. 바뀐 데이터가 조회됨
- 멱등은 외부 요인으로 중간에 리소스가 변경되는 것 까지는 고려하지 않음
- 내가 동일한 요청을 똑같이 요청했을 때 멱등 한 것만 고려함
- PATCH의 멱등성
- 기본적으로 PATCH는 멱등하지 않음
- 단, PUT과 동일한 방식으로 할 경우 멱등성을 가짐
예시(아래 더보기 클릭)
Put 예시
기존의 리소스
{
id: 1,
name: "김철수",
age: 15
}
PUT /users/1
{
age: 20
}
변경된 리소스
{
id: 1,
name: NULL,
age: 20
}
put의 경우 덮어쓸 데이터가 Body에 위치해야 하며 기존의 리소스가 해당 데이터로 완전히 덮어 써짐
Patch 예시
기존의 리소스
{
id: 1,
name: "김철수",
age: 15
}
PATCH /users/1
{
age: {
action: $increase,
value: 1
}
}
변경된 리소스
{
id: 1,
name: "김철수",
age: 16
}
- PATCH의 경우 HTTP 스펙상 구현 방법에 제한이 없음
- 그렇기 때문에 요청 Body에 꼭 덮어쓸 데이터만 있을 필요가 없음
- 위 예시 처럼 덮어쓸 데이터가 아닌 동작을 지정할 수 있음
- 위 예시가 동일한 요청을 보내면, 매 요청마다 age가 1씩 증가함
- 즉 멱등성을 가지지 않음
- 다만 Put의 구현처럼 메시지 Body에 덮어쓸 데이터만 위치 시키면 Put과 같이 멱등성을 지님
🟪 캐시 가능
- 응답 결과 리소스를 캐시 해서 사용할 수 있는가?
- 용량이 큰 이미지 다운 → 똑같은 이미지 보여줘야 할 경우 다시 다운로드 받을 필요 X → 내 로컬 브라우저에 저장(캐시)
- GET, HEAD, POST, PATCH 캐시 가능
- 실제로는 GET, HEAD 정도만 캐시로 사용 → URL을 key로 잡아 캐시 하면 되므로 심플
- POST, PATCH는 본문 내용까지 캐시 키로 고려해야 하는데 구현이 쉽지 않음
🚩 실무에서 헷갈리는 URI 설계
1) Soft delete (DELETE? PATCH? PUT?)
- 예시 ) 데이터를 삭제하고자 할 때 실제로 db에서 state 값만 변경하는 경우
- 개인적인 의견으로는 DELETE 사용하는 것이 바람직하다고 생각
- 요청 메서드에 클라이언트의 의도가 명확하게 드러나지만, 내부 동작은 서버에 감춰져 있기 때문
- 실제 동작으로는 PATCH 가 더 적합해 보이지만 안전 복구 메커니즘을 생각하였을 경우 PATCH는 기본적으로 멱등하지 않으므로 DELETE가 더 적합하다고 생각
- Soft Delete때 DELETE 메서드를 사용해야 하는 이유
- stackoverflow 글 보기
2) DELETE 요청 메서드로 자원 삭제 시 사용자의 민감 정보가 요청에 포함되어야 하는 경우
- 인증을 위해 사용자의 민감 정보가 요청에 포함되어야 할 경우 Request Header 방식이 적합해 보임
- URL query string parameter
- 간편하지만 보안 상 취약하므로 추천하지 않는 방식
- Request Body parameter
A payload within a DELETE request message has no defined semantics; sending a payload body on a DELETE request might cause some existing implementations to reject the request.
- Query string 방식보다는 보안은 좋음
- 단, DELETE 요청 시 Request에 body를 포함시키는 것을 금지하지는 않지만 body에 요청 메시지가 있는 경우 요청을 거절하는 서버가 많음
- Request Header parameter (추천)
- Query string 보다는 보안이 조금 더 좋고 Body parameter 방식보다는 더 일반적인 방법
- 예시
- JWT 토큰 → Authorization 헤더에 Bearer 타입 명시 후 인증 정보 담긴 JWT 토큰 넣어서 보내기
- 사용자의 민감 개인 정보 → Authorization 헤더에 Basic 타입 명시 후 개인 정보 BASE64 인코딩하여 HTTPS로 보내기
참고
- 삽화 및 내용 참고 (모든 개발자를 위한 HTTP 웹 기본 지식)
모든 개발자를 위한 HTTP 웹 기본 지식 | 김영한 - 인프런
김영한 | 실무에 꼭 필요한 HTTP 핵심 기능과 올바른 HTTP API 설계 방법을 학습합니다., [사진] 📣 확인해주세요!본 강의는 자바 스프링 완전 정복 시리즈의 세 번째 강의입니다. 우아한형제들 최연
www.inflearn.com
HTTP - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. HTTP(HyperText Transfer Protocol, 문화어: 초본문전송규약, 하이퍼본문전송규약)는 W3 상에서 정보를 주고받을 수 있는 프로토콜이다. 주로 HTML 문서를 주고받는 데에
ko.wikipedia.org
'HTTP' 카테고리의 다른 글
| RESTful API란? (0) | 2024.03.23 |
|---|---|
| OpenFeign(MSA CURL) (0) | 2024.03.21 |
| (HTTP)인터넷 네트워크 (0) | 2022.05.23 |